Each day there is probably work done to improve performance of the InnoDB storage engine and remove bottlenecks and scalability issues. Hence there was another one I wanted to highlight:
Scalability issues due to tables without primary keys
This scalability issue is caused by the usage of tables without primary keys. This issue typically shows itself as contention on the InnoDB dict_sys mutex. Now the dict_sys mutex controls access to the data dictionary. This mutex is used at various places. I will only mention a few of them:
- During operations such as opening and closing table handles, or
- When accessing I_S tables, or
- During undo of a freshly inserted row, or
- During other data dictionary modification operations such as CREATE TABLE, or
- Within the “Persistent Stats” subsystem, among other things.
Of course this list is not exhaustive but should give you a good picture of how heavily it is used.
But the thing is when you are mainly debugging contention related to a data dictionary control structure, you start to look off at something that is directly related to data dictionary modifications. You look for execution of CREATE TABLE, DROP TABLE, TRUNCATE TABLE, etc. But what if none of that is actually causing the contention on the dict_sys mutex? Are you aware when generating “row-id” values, for tables without explicit primary keys, or without non-nullable unique keys, dict_sys mutex is acquired. So INSERTs to tables with implicit primary keys is a InnoDB system-wide contention point.
Let’s also take a look at the relevant source code.
Firstly, below is the function that does the row-id allocation which is defined in the file storage/innobase/row/row0ins.cc
3060 /***********************************************************//**
3061 Allocates a row id for row and inits the node->index field. */
3062 UNIV_INLINE
3063 void
3064 row_ins_alloc_row_id_step(
3065 /*======================*/
3066 ins_node_t* node) /*!< in: row insert node */ 3067 { 3068 row_id_t row_id; 3069 3070 ut_ad(node->state == INS_NODE_ALLOC_ROW_ID);
3071
3072 if (dict_index_is_unique(dict_table_get_first_index(node->table))) {
3073
3074 /* No row id is stored if the clustered index is unique */
3075
3076 return;
3077 }
3078
3079 /* Fill in row id value to row */
3080
3081 row_id = dict_sys_get_new_row_id();
3082
3083 dict_sys_write_row_id(node->row_id_buf, row_id);
3084 }Secondly, below is the function that actually generates the row-id which is defined in the file storage/innobase/include/dict0boot.ic
26 /**********************************************************************//**
27 Returns a new row id.
28 @return the new id */
29 UNIV_INLINE
30 row_id_t
31 dict_sys_get_new_row_id(void)
32 /*=========================*/
33 {
34 row_id_t id;
35
36 mutex_enter(&(dict_sys->mutex));
37
38 id = dict_sys->row_id;
39
40 if (0 == (id % DICT_HDR_ROW_ID_WRITE_MARGIN)) {
41
42 dict_hdr_flush_row_id();
43 }
44
45 dict_sys->row_id++;
46
47 mutex_exit(&(dict_sys->mutex));
48
49 return(id);
50 }Finally, I would like to share results of a few benchmarks that I conducted in order to show you how this affects performance.
Benchmarking affects of non-presence of primary keys
First off all, let me share information about the host that was used in the benchmarks. I will also share the MySQL version and InnoDB configuration used.
Hardware
The host was a “hi1.4xlarge” Amazon EC2 instance. The instance comes with 16 vCPUs and 60.5GB of memory. The instance storage consists of 2×1024 SSD-backed storage volumes, and the instance is connected to a 10 Gigabit ethernet network. So the IO performance is very decent. I created a RAID 0 array from the 2 instance storage volumes and created XFS filesystem on the resultant software RAID 0 volume. This configuration would allows us to get the best possible IO performance out of the instance.
MySQL
The MySQL version used was 5.5.34 MySQL Community Server, and the InnoDB configuration looked as follows:
innodb-flush-method = O_DIRECT innodb-log-files-in-group = 2 innodb-log-file-size = 512M innodb-flush-log-at-trx-commit = 2 innodb-file-per-table = 1 innodb-buffer-pool-size = 42G innodb-buffer-pool-instances = 8 innodb-io-capacity = 10000 innodb_adaptive_hash_index = 1
I conducted two different types of benchmarks, and both of them were done by using sysbench.
First one involved benchmarking the performance of single-row INSERTs for tables with and without explicit primary keys. That’s what I would be showing first.
Single-row INSERTs
The tables were generated as follows for the benchmark involving tables with primary keys:
sysbench --test=/root/sysbench/sysbench/tests/db/insert.lua --oltp-tables-count=64 --oltp-table-size=1000000 --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test prepare
This resulted in the following table being created:
CREATE TABLE `sbtest1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `k_1` (`k`) ) ENGINE=InnoDB
While the tables without primary keys were generated as follows:
sysbench --test=/root/sysbench/sysbench/tests/db/insert.lua --oltp-tables-count=64 --oltp-table-size=1000000 --oltp-secondary --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test prepare
This resulted in the tables being created with the following structure:
CREATE TABLE `sbtest1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `k` int(10) unsigned NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', KEY `xid` (`id`), KEY `k_1` (`k`) ) ENGINE=InnoDB
The actual benchmark for the table with primary keys was run as follows:
sysbench --test=/root/sysbench/sysbench/tests/db/insert.lua --oltp-tables-count=64 --oltp-table-size=1000000 --oltp-dist-type=uniform --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test --max-time=300 --num-threads=16 --max-requests=0 --report-interval=1 run
While the actual benchmark for the table without primary keys was run as follows:
sysbench --test=/root/sysbench/sysbench/tests/db/insert.lua --oltp-tables-count=64 --oltp-table-size=1000000 --oltp-secondary --oltp-dist-type=uniform --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test --max-time=300 --num-threads=16 --max-requests=0 --report-interval=1 run
Note that the benchmarks were run with three variations in the number of concurrent threads used by sysbench: 16, 32 and 64.
Below are how the graphs look like for each of these benchmarks.
Image may be NSFW.
Clik here to view.
Image may be NSFW.
Clik here to view.
Image may be NSFW.
Clik here to view.
Some key things to note from the graphs are that the throughput of the INSERTs to the tables without explicit primary keys never goes above 87% of the throughput of the INSERTs to the tables with primary keys defined. Furthermore, as we increase the concurrency downward spikes start appearing. These become more apparent when we move to a concurrency of 64 threads. This is expected, because the contention is supposed to increase as we increase the concurrency of operations that contend on the dict_sys mutex.
Now let’s take a look at how this impacts the bulk load performance.
Bulk Loads
The bulk loads to the tables with primary keys were performed as follows:
sysbench --test=/root/sysbench/sysbench/tests/db/parallel_prepare.lua --oltp-tables-count=64 --oltp-table-size=1000000 --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test --num-threads=16 run
While the bulk loads to the tables without primary keys were performed as follows:
sysbench --test=/root/sysbench/sysbench/tests/db/parallel_prepare.lua --oltp-tables-count=64 --oltp-table-size=1000000 --oltp-secondary --mysql-table-engine=innodb --mysql-user=root --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-db=test --num-threads=16 run
Note that the benchmarks were again run with three variations in the number of concurrent threads used by sysbench: 16, 32 and 64.
Below is what the picture is portrayed by the graph.
Image may be NSFW.
Clik here to view.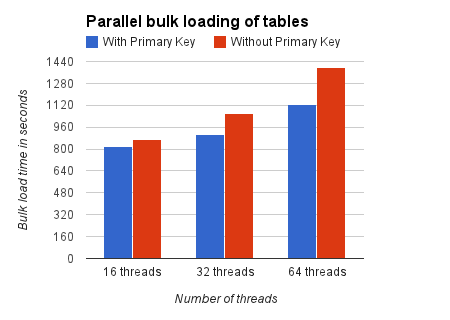
Here again, you can see how the bulk load time increases as we increase the number of concurrent threads. This against points to the increase in contention on the dict_sys mutex. With 16 threads the bulk load time for tables without primary keys is 107% more than the bulk load time for the tables with primary keys. This increases to 116% with 32 threads and finally 124% with 64 threads.
Conclusion
Tables without primary keys cause a wide range of contention because they rely on acquiring dict_sys mutex to generate row-id values. This mutex is used at critical places within InnoDB. Hence the affect of large amount of INSERTs to tables without primary keys is not only isolated to that table alone but can be seen very widely. There are a number of times I have seen tables without primary keys being used in many different scenarios that include simple INSERTs to these tables as well as multi-row INSERTs as a result of, for example, INSERT … SELECT into a table that is being temporarily created. The advice is always to have primary keys present in your tables. Hopefully I have been able to highlight the true impact non-presence of primary keys can have.
The post InnoDB scalability issues due to tables without primary keys appeared first on MySQL Performance Blog.